Source code
Revision control
Copy as Markdown
Other Tools
//! [![github]](https://github.com/dtolnay/zmij) [![crates-io]](https://crates.io/crates/zmij) [![docs-rs]](https://docs.rs/zmij)
//!
//! [github]: https://img.shields.io/badge/github-8da0cb?style=for-the-badge&labelColor=555555&logo=github
//! [crates-io]: https://img.shields.io/badge/crates.io-fc8d62?style=for-the-badge&labelColor=555555&logo=rust
//! [docs-rs]: https://img.shields.io/badge/docs.rs-66c2a5?style=for-the-badge&labelColor=555555&logo=docs.rs
//!
//! <br>
//!
//! A double-to-string conversion algorithm based on [Schubfach] and [yy].
//!
//! This Rust implementation is a line-by-line port of Victor Zverovich's
//! implementation in C++, <https://github.com/vitaut/zmij>.
//!
//! [Schubfach]: https://fmt.dev/papers/Schubfach4.pdf
//!
//! <br>
//!
//! # Example
//!
//! ```
//! fn main() {
//! let mut buffer = zmij::Buffer::new();
//! let printed = buffer.format(1.234);
//! assert_eq!(printed, "1.234");
//! }
//! ```
//!
//! <br>
//!
//! ## Performance
//!
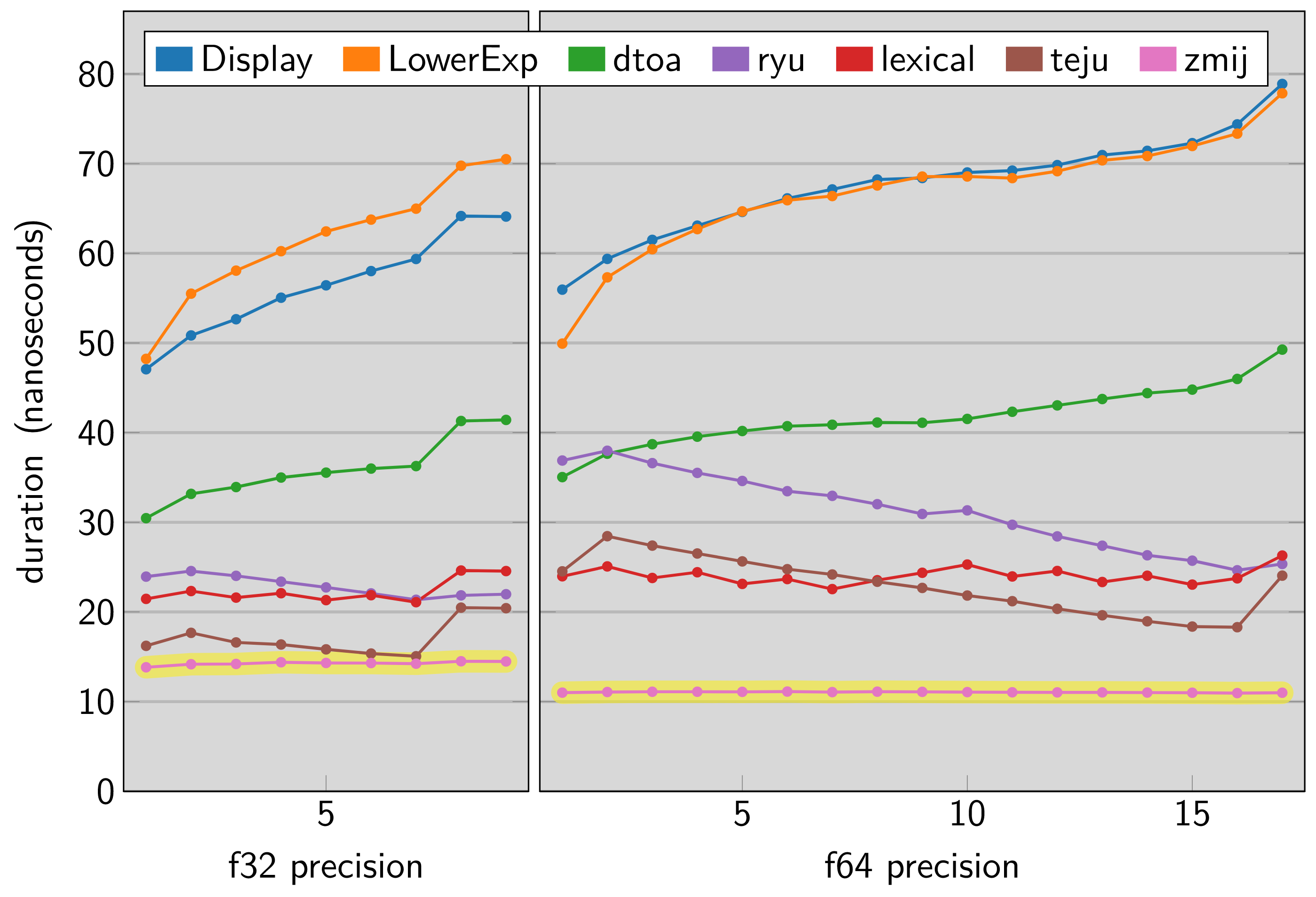
//! The [dtoa-benchmark] compares this library and other Rust floating point
//! formatting implementations across a range of precisions. The vertical axis
//! in this chart shows nanoseconds taken by a single execution of
//! `zmij::Buffer::new().format_finite(value)` so a lower result indicates a
//! faster library.
//!
//! [dtoa-benchmark]: https://github.com/dtolnay/dtoa-benchmark
//!
//! 
{kind=link}
#![no_std]
#![doc(html_root_url = "https://docs.rs/zmij/1.0.20")]
#![deny(unsafe_op_in_unsafe_fn)]
#![allow(non_camel_case_types, non_snake_case)]
#![allow(
clippy::blocks_in_conditions,
clippy::cast_possible_truncation,
clippy::cast_possible_wrap,
clippy::cast_ptr_alignment,
clippy::cast_sign_loss,
clippy::doc_markdown,
clippy::incompatible_msrv,
clippy::items_after_statements,
clippy::many_single_char_names,
clippy::modulo_one,
clippy::must_use_candidate,
clippy::needless_doctest_main,
clippy::never_loop,
clippy::redundant_else,
clippy::similar_names,
clippy::too_many_arguments,
clippy::too_many_lines,
clippy::unreadable_literal,
clippy::used_underscore_items,
clippy::while_immutable_condition,
clippy::wildcard_imports
)]
#[cfg(zmij_no_select_unpredictable)]
mod hint;
#[cfg(all(target_arch = "x86_64", target_feature = "sse2", not(miri)))]
mod stdarch_x86;
#[cfg(test)]
mod tests;
mod traits;
#[cfg(all(any(target_arch = "aarch64", target_arch = "x86_64"), not(miri)))]
use core::arch::asm;
#[cfg(not(zmij_no_select_unpredictable))]
use core::hint;
use core::mem::{self, MaybeUninit};
use core::ptr;
use core::slice;
use core::str;
#[cfg(feature = "no-panic")]
use no_panic::no_panic;
const BUFFER_SIZE: usize = 24;
const NAN: &str = "NaN";
const INFINITY: &str = "inf";
const NEG_INFINITY: &str = "-inf";
// Returns true_value if lhs < rhs, else false_value, without branching.
#[inline]
fn select_if_less(lhs: u64, rhs: u64, true_value: i64, false_value: i64) -> i64 {
hint::select_unpredictable(lhs < rhs, true_value, false_value)
}
#[derive(Copy, Clone)]
#[cfg_attr(test, derive(Debug, PartialEq))]
struct uint128 {
hi: u64,
lo: u64,
}
// Use umul128_hi64 for division.
const USE_UMUL128_HI64: bool = cfg!(target_vendor = "apple");
// Computes 128-bit result of multiplication of two 64-bit unsigned integers.
const fn umul128(x: u64, y: u64) -> u128 {
x as u128 * y as u128
}
const fn umul128_hi64(x: u64, y: u64) -> u64 {
(umul128(x, y) >> 64) as u64
}
#[cfg_attr(feature = "no-panic", no_panic)]
fn umul192_hi128(x_hi: u64, x_lo: u64, y: u64) -> uint128 {
let p = umul128(x_hi, y);
let lo = (p as u64).wrapping_add((umul128(x_lo, y) >> 64) as u64);
uint128 {
hi: (p >> 64) as u64 + u64::from(lo < p as u64),
lo,
}
}
// Computes high 64 bits of multiplication of x and y, discards the least
// significant bit and rounds to odd, where x = uint128_t(x_hi << 64) | x_lo.
#[cfg_attr(feature = "no-panic", no_panic)]
fn umulhi_inexact_to_odd<UInt>(x_hi: u64, x_lo: u64, y: UInt) -> UInt
where
UInt: traits::UInt,
{
let num_bits = mem::size_of::<UInt>() * 8;
if num_bits == 64 {
let p = umul192_hi128(x_hi, x_lo, y.into());
UInt::truncate(p.hi | u64::from((p.lo >> 1) != 0))
} else {
let p = (umul128(x_hi, y.into()) >> 32) as u64;
UInt::enlarge((p >> 32) as u32 | u32::from((p as u32 >> 1) != 0))
}
}
trait FloatTraits: traits::Float {
const NUM_BITS: i32;
const NUM_SIG_BITS: i32 = Self::MANTISSA_DIGITS as i32 - 1;
const NUM_EXP_BITS: i32 = Self::NUM_BITS - Self::NUM_SIG_BITS - 1;
const EXP_MASK: i32 = (1 << Self::NUM_EXP_BITS) - 1;
const EXP_BIAS: i32 = (1 << (Self::NUM_EXP_BITS - 1)) - 1;
const EXP_OFFSET: i32 = Self::EXP_BIAS + Self::NUM_SIG_BITS;
type SigType: traits::UInt;
const IMPLICIT_BIT: Self::SigType;
fn to_bits(self) -> Self::SigType;
fn is_negative(bits: Self::SigType) -> bool {
(bits >> (Self::NUM_BITS - 1)) != Self::SigType::from(0)
}
fn get_sig(bits: Self::SigType) -> Self::SigType {
bits & (Self::IMPLICIT_BIT - Self::SigType::from(1))
}
fn get_exp(bits: Self::SigType) -> i64 {
(bits << 1u8 >> (Self::NUM_SIG_BITS + 1)).into() as i64
}
}
impl FloatTraits for f32 {
const NUM_BITS: i32 = 32;
const IMPLICIT_BIT: u32 = 1 << Self::NUM_SIG_BITS;
type SigType = u32;
fn to_bits(self) -> Self::SigType {
self.to_bits()
}
}
impl FloatTraits for f64 {
const NUM_BITS: i32 = 64;
const IMPLICIT_BIT: u64 = 1 << Self::NUM_SIG_BITS;
type SigType = u64;
fn to_bits(self) -> Self::SigType {
self.to_bits()
}
}
#[repr(C, align(64))]
struct Pow10SignificandsTable {
data: [u64; if Self::COMPRESS {
0
} else {
Self::NUM_POW10 * 2
}],
}
impl Pow10SignificandsTable {
const COMPRESS: bool = false;
const SPLIT_TABLES: bool = !Self::COMPRESS && cfg!(target_arch = "aarch64");
const NUM_POW10: usize = 617;
unsafe fn get_unchecked(&self, dec_exp: i32) -> uint128 {
const DEC_EXP_MIN: i32 = -292;
if Self::COMPRESS {
let i = dec_exp - DEC_EXP_MIN;
// 672 bytes of data
#[rustfmt::skip]
static POW10S: [u64; 28] = [
0x8000000000000000, 0xa000000000000000, 0xc800000000000000,
0xfa00000000000000, 0x9c40000000000000, 0xc350000000000000,
0xf424000000000000, 0x9896800000000000, 0xbebc200000000000,
0xee6b280000000000, 0x9502f90000000000, 0xba43b74000000000,
0xe8d4a51000000000, 0x9184e72a00000000, 0xb5e620f480000000,
0xe35fa931a0000000, 0x8e1bc9bf04000000, 0xb1a2bc2ec5000000,
0xde0b6b3a76400000, 0x8ac7230489e80000, 0xad78ebc5ac620000,
0xd8d726b7177a8000, 0x878678326eac9000, 0xa968163f0a57b400,
0xd3c21bcecceda100, 0x84595161401484a0, 0xa56fa5b99019a5c8,
0xcecb8f27f4200f3a,
];
#[rustfmt::skip]
static HIGH_PARTS: [uint128; 23] = [
uint128 { hi: 0xaf8e5410288e1b6f, lo: 0x07ecf0ae5ee44dda },
uint128 { hi: 0xb1442798f49ffb4a, lo: 0x99cd11cfdf41779d },
uint128 { hi: 0xb2fe3f0b8599ef07, lo: 0x861fa7e6dcb4aa15 },
uint128 { hi: 0xb4bca50b065abe63, lo: 0x0fed077a756b53aa },
uint128 { hi: 0xb67f6455292cbf08, lo: 0x1a3bc84c17b1d543 },
uint128 { hi: 0xb84687c269ef3bfb, lo: 0x3d5d514f40eea742 },
uint128 { hi: 0xba121a4650e4ddeb, lo: 0x92f34d62616ce413 },
uint128 { hi: 0xbbe226efb628afea, lo: 0x890489f70a55368c },
uint128 { hi: 0xbdb6b8e905cb600f, lo: 0x5400e987bbc1c921 },
uint128 { hi: 0xbf8fdb78849a5f96, lo: 0xde98520472bdd034 },
uint128 { hi: 0xc16d9a0095928a27, lo: 0x75b7053c0f178294 },
uint128 { hi: 0xc350000000000000, lo: 0x0000000000000000 },
uint128 { hi: 0xc5371912364ce305, lo: 0x6c28000000000000 },
uint128 { hi: 0xc722f0ef9d80aad6, lo: 0x424d3ad2b7b97ef6 },
uint128 { hi: 0xc913936dd571c84c, lo: 0x03bc3a19cd1e38ea },
uint128 { hi: 0xcb090c8001ab551c, lo: 0x5cadf5bfd3072cc6 },
uint128 { hi: 0xcd036837130890a1, lo: 0x36dba887c37a8c10 },
uint128 { hi: 0xcf02b2c21207ef2e, lo: 0x94f967e45e03f4bc },
uint128 { hi: 0xd106f86e69d785c7, lo: 0xe13336d701beba52 },
uint128 { hi: 0xd31045a8341ca07c, lo: 0x1ede48111209a051 },
uint128 { hi: 0xd51ea6fa85785631, lo: 0x552a74227f3ea566 },
uint128 { hi: 0xd732290fbacaf133, lo: 0xa97c177947ad4096 },
uint128 { hi: 0xd94ad8b1c7380874, lo: 0x18375281ae7822bc },
];
#[rustfmt::skip]
static FIXUPS: [u32; 20] = [
0x05271b1f, 0x00000c20, 0x00003200, 0x12100020,
0x00000000, 0x06000000, 0xc16409c0, 0xaf26700f,
0xeb987b07, 0x0000000d, 0x00000000, 0x66fbfffe,
0xb74100ec, 0xa0669fe8, 0xedb21280, 0x00000686,
0x0a021200, 0x29b89c20, 0x08bc0eda, 0x00000000,
];
let m = unsafe { *POW10S.get_unchecked(((i + 11) % 28) as usize) };
let h = unsafe { *HIGH_PARTS.get_unchecked(((i + 11) / 28) as usize) };
let h1 = umul128_hi64(h.lo, m);
let c0 = h.lo.wrapping_mul(m);
let c1 = h1.wrapping_add(h.hi.wrapping_mul(m));
let c2 = u64::from(c1 < h1) + umul128_hi64(h.hi, m);
let mut result = if (c2 >> 63) != 0 {
uint128 { hi: c2, lo: c1 }
} else {
uint128 {
hi: (c2 << 1) | (c1 >> 63),
lo: (c1 << 1) | (c0 >> 63),
}
};
result.lo -=
u64::from((unsafe { *FIXUPS.get_unchecked((i >> 5) as usize) } >> (i & 31)) & 1);
return result;
}
if !Self::SPLIT_TABLES {
let index = ((dec_exp - DEC_EXP_MIN) * 2) as usize;
return uint128 {
hi: unsafe { *self.data.get_unchecked(index) },
lo: unsafe { *self.data.get_unchecked(index + 1) },
};
}
unsafe {
#[cfg_attr(
not(all(any(target_arch = "x86_64", target_arch = "aarch64"), not(miri))),
allow(unused_mut)
)]
let mut hi = self
.data
.as_ptr()
.offset(Self::NUM_POW10 as isize + DEC_EXP_MIN as isize - 1);
#[cfg_attr(
not(all(any(target_arch = "x86_64", target_arch = "aarch64"), not(miri))),
allow(unused_mut)
)]
let mut lo = hi.add(Self::NUM_POW10);
// Force indexed loads.
#[cfg(all(any(target_arch = "x86_64", target_arch = "aarch64"), not(miri)))]
asm!("/*{0}{1}*/", inout(reg) hi, inout(reg) lo);
uint128 {
hi: *hi.offset(-dec_exp as isize),
lo: *lo.offset(-dec_exp as isize),
}
}
}
#[cfg(test)]
fn get(&self, dec_exp: i32) -> uint128 {
const DEC_EXP_MIN: i32 = -292;
assert!((DEC_EXP_MIN..DEC_EXP_MIN + Self::NUM_POW10 as i32).contains(&dec_exp));
unsafe { self.get_unchecked(dec_exp) }
}
}
// 128-bit significands of powers of 10 rounded down.
// Generation with 192-bit arithmetic and compression by Dougall Johnson.
static POW10_SIGNIFICANDS: Pow10SignificandsTable = {
let mut data = [0; if Pow10SignificandsTable::COMPRESS {
0
} else {
Pow10SignificandsTable::NUM_POW10 * 2
}];
struct uint192 {
w0: u64, // least significant
w1: u64,
w2: u64, // most significant
}
// First element, rounded up to cancel out rounding down in the
// multiplication, and minimize significant bits.
let mut current = uint192 {
w0: 0xe000000000000000,
w1: 0x25e8e89c13bb0f7a,
w2: 0xff77b1fcbebcdc4f,
};
let ten = 0xa000000000000000;
let mut i = 0;
while i < Pow10SignificandsTable::NUM_POW10 && !Pow10SignificandsTable::COMPRESS {
if Pow10SignificandsTable::SPLIT_TABLES {
data[Pow10SignificandsTable::NUM_POW10 - i - 1] = current.w2;
data[Pow10SignificandsTable::NUM_POW10 * 2 - i - 1] = current.w1;
} else {
data[i * 2] = current.w2;
data[i * 2 + 1] = current.w1;
}
let h0: u64 = umul128_hi64(current.w0, ten);
let h1: u64 = umul128_hi64(current.w1, ten);
let c0: u64 = h0.wrapping_add(current.w1.wrapping_mul(ten));
let c1: u64 = ((c0 < h0) as u64 + h1).wrapping_add(current.w2.wrapping_mul(ten));
let c2: u64 = (c1 < h1) as u64 + umul128_hi64(current.w2, ten); // dodgy carry
// normalise
if (c2 >> 63) != 0 {
current = uint192 {
w0: c0,
w1: c1,
w2: c2,
};
} else {
current = uint192 {
w0: c0 << 1,
w1: c1 << 1 | c0 >> 63,
w2: c2 << 1 | c1 >> 63,
};
}
i += 1;
}
Pow10SignificandsTable { data }
};
// Computes the decimal exponent as floor(log10(2**bin_exp)) if regular or
// floor(log10(3/4 * 2**bin_exp)) otherwise, without branching.
const fn compute_dec_exp(bin_exp: i32, regular: bool) -> i32 {
debug_assert!(bin_exp >= -1334 && bin_exp <= 2620);
// log10_3_over_4_sig = -log10(3/4) * 2**log10_2_exp rounded to a power of 2
const LOG10_3_OVER_4_SIG: i32 = 131_072;
// log10_2_sig = round(log10(2) * 2**log10_2_exp)
const LOG10_2_SIG: i32 = 315_653;
const LOG10_2_EXP: i32 = 20;
(bin_exp * LOG10_2_SIG - !regular as i32 * LOG10_3_OVER_4_SIG) >> LOG10_2_EXP
}
#[inline]
const fn do_compute_exp_shift(bin_exp: i32, dec_exp: i32) -> u8 {
debug_assert!(dec_exp >= -350 && dec_exp <= 350);
// log2_pow10_sig = round(log2(10) * 2**log2_pow10_exp) + 1
const LOG2_POW10_SIG: i32 = 217_707;
const LOG2_POW10_EXP: i32 = 16;
// pow10_bin_exp = floor(log2(10**-dec_exp))
let pow10_bin_exp = (-dec_exp * LOG2_POW10_SIG) >> LOG2_POW10_EXP;
// pow10 = ((pow10_hi << 64) | pow10_lo) * 2**(pow10_bin_exp - 127)
(bin_exp + pow10_bin_exp + 1) as u8
}
struct ExpShiftTable {
data: [u8; if Self::ENABLE {
f64::EXP_MASK as usize + 1
} else {
1
}],
}
impl ExpShiftTable {
const ENABLE: bool = true;
}
static EXP_SHIFTS: ExpShiftTable = {
let mut data = [0u8; if ExpShiftTable::ENABLE {
f64::EXP_MASK as usize + 1
} else {
1
}];
let mut raw_exp = 0;
while raw_exp < data.len() && ExpShiftTable::ENABLE {
let mut bin_exp = raw_exp as i32 - f64::EXP_OFFSET;
if raw_exp == 0 {
bin_exp += 1;
}
let dec_exp = compute_dec_exp(bin_exp, true);
data[raw_exp] = do_compute_exp_shift(bin_exp, dec_exp) as u8;
raw_exp += 1;
}
ExpShiftTable { data }
};
// Computes a shift so that, after scaling by a power of 10, the intermediate
// result always has a fixed 128-bit fractional part (for double).
//
// Different binary exponents can map to the same decimal exponent, but place
// the decimal point at different bit positions. The shift compensates for this.
//
// For example, both 3 * 2**59 and 3 * 2**60 have dec_exp = 2, but dividing by
// 10^dec_exp puts the decimal point in different bit positions:
// 3 * 2**59 / 100 = 1.72...e+16 (needs shift = 1 + 1)
// 3 * 2**60 / 100 = 3.45...e+16 (needs shift = 2 + 1)
#[inline]
unsafe fn compute_exp_shift<UInt, const ONLY_REGULAR: bool>(bin_exp: i32, dec_exp: i32) -> u8
where
UInt: traits::UInt,
{
let num_bits = mem::size_of::<UInt>() * 8;
if num_bits == 64 && ExpShiftTable::ENABLE && ONLY_REGULAR {
unsafe {
*EXP_SHIFTS
.data
.as_ptr()
.add((bin_exp + f64::EXP_OFFSET) as usize)
}
} else {
do_compute_exp_shift(bin_exp, dec_exp)
}
}
#[cfg_attr(feature = "no-panic", no_panic)]
fn count_trailing_nonzeros(x: u64) -> usize {
// We count the number of bytes until there are only zeros left.
// The code is equivalent to
// 8 - x.leading_zeros() / 8
// but if the BSR instruction is emitted (as gcc on x64 does with default
// settings), subtracting the constant before dividing allows the compiler
// to combine it with the subtraction which it inserts due to BSR counting
// in the opposite direction.
//
// Additionally, the BSR instruction requires a zero check. Since the high
// bit is unused we can avoid the zero check by shifting the datum left by
// one and inserting a sentinel bit at the end. This can be faster than the
// automatically inserted range check.
(70 - ((x.to_le() << 1) | 1).leading_zeros() as usize) / 8
}
// Align data since unaligned access may be slower when crossing a
// hardware-specific boundary.
#[repr(C, align(2))]
struct Digits2([u8; 200]);
static DIGITS2: Digits2 = Digits2(
*b"0001020304050607080910111213141516171819\
2021222324252627282930313233343536373839\
4041424344454647484950515253545556575859\
6061626364656667686970717273747576777879\
8081828384858687888990919293949596979899",
);
// Converts value in the range [0, 100) to a string. GCC generates a bit better
// code when value is pointer-size (https://www.godbolt.org/z/5fEPMT1cc).
#[cfg_attr(feature = "no-panic", no_panic)]
unsafe fn digits2(value: usize) -> &'static u16 {
debug_assert!(value < 100);
#[allow(clippy::cast_ptr_alignment)]
unsafe {
&*DIGITS2.0.as_ptr().cast::<u16>().add(value)
}
}
const DIV10K_EXP: i32 = 40;
const DIV10K_SIG: u32 = ((1u64 << DIV10K_EXP) / 10000 + 1) as u32;
const NEG10K: u32 = ((1u64 << 32) - 10000) as u32;
const DIV100_EXP: i32 = 19;
const DIV100_SIG: u32 = (1 << DIV100_EXP) / 100 + 1;
const NEG100: u32 = (1 << 16) - 100;
const DIV10_EXP: i32 = 10;
const DIV10_SIG: u32 = (1 << DIV10_EXP) / 10 + 1;
const NEG10: u32 = (1 << 8) - 10;
const ZEROS: u64 = 0x0101010101010101 * b'0' as u64;
#[cfg_attr(feature = "no-panic", no_panic)]
fn to_bcd8(abcdefgh: u64) -> u64 {
// An optimization from Xiang JunBo.
// Three steps BCD. Base 10000 -> base 100 -> base 10.
// div and mod are evaluated simultaneously as, e.g.
// (abcdefgh / 10000) << 32 + (abcdefgh % 10000)
// == abcdefgh + (2**32 - 10000) * (abcdefgh / 10000)))
// where the division on the RHS is implemented by the usual multiply + shift
// trick and the fractional bits are masked away.
let abcd_efgh =
abcdefgh + u64::from(NEG10K) * ((abcdefgh * u64::from(DIV10K_SIG)) >> DIV10K_EXP);
let ab_cd_ef_gh = abcd_efgh
+ u64::from(NEG100) * (((abcd_efgh * u64::from(DIV100_SIG)) >> DIV100_EXP) & 0x7f0000007f);
let a_b_c_d_e_f_g_h = ab_cd_ef_gh
+ u64::from(NEG10)
* (((ab_cd_ef_gh * u64::from(DIV10_SIG)) >> DIV10_EXP) & 0xf000f000f000f);
a_b_c_d_e_f_g_h.to_be()
}
unsafe fn write_if(buffer: *mut u8, digit: u32, condition: bool) -> *mut u8 {
unsafe {
*buffer = b'0' + digit as u8;
buffer.add(usize::from(condition))
}
}
unsafe fn write8(buffer: *mut u8, value: u64) {
unsafe {
buffer.cast::<u64>().write_unaligned(value);
}
}
// Writes a significand and removes trailing zeros. value has up to 17 decimal
// digits (16-17 for normals) for double (num_bits == 64) and up to 9 digits
// (8-9 for normals) for float. The significant digits start from buffer[1].
// buffer[0] may contain '0' after this function if the leading digit is zero.
#[cfg_attr(feature = "no-panic", no_panic)]
#[inline]
unsafe fn write_significand<Float>(mut buffer: *mut u8, value: u64, extra_digit: bool) -> *mut u8
where
Float: FloatTraits,
{
if Float::NUM_BITS == 32 {
buffer = unsafe { write_if(buffer, (value / 100_000_000) as u32, extra_digit) };
let bcd = to_bcd8(value % 100_000_000);
unsafe {
write8(buffer, bcd + ZEROS);
return buffer.add(count_trailing_nonzeros(bcd));
}
}
#[cfg(not(any(
all(target_arch = "aarch64", target_feature = "neon", not(miri)),
all(target_arch = "x86_64", target_feature = "sse2", not(miri)),
)))]
{
// Digits/pairs of digits are denoted by letters: value = abbccddeeffgghhii.
let abbccddee = (value / 100_000_000) as u32;
let ffgghhii = (value % 100_000_000) as u32;
buffer = unsafe { write_if(buffer, abbccddee / 100_000_000, extra_digit) };
let bcd = to_bcd8(u64::from(abbccddee % 100_000_000));
unsafe {
write8(buffer, bcd + ZEROS);
}
if ffgghhii == 0 {
return unsafe { buffer.add(count_trailing_nonzeros(bcd)) };
}
let bcd = to_bcd8(u64::from(ffgghhii));
unsafe {
write8(buffer.add(8), bcd + ZEROS);
buffer.add(8).add(count_trailing_nonzeros(bcd))
}
}
#[cfg(all(target_arch = "aarch64", target_feature = "neon", not(miri)))]
{
// An optimized version for NEON by Dougall Johnson.
use core::arch::aarch64::*;
const NEG10K: i32 = -10000 + 0x10000;
#[repr(C, align(64))]
struct Consts {
mul_const: u64,
hundred_million: u64,
multipliers32: int32x4_t,
multipliers16: int16x8_t,
}
static CONSTS: Consts = Consts {
mul_const: 0xabcc77118461cefd,
hundred_million: 100000000,
multipliers32: unsafe {
mem::transmute::<[i32; 4], int32x4_t>([
DIV10K_SIG as i32,
NEG10K,
(DIV100_SIG << 12) as i32,
NEG100 as i32,
])
},
multipliers16: unsafe {
mem::transmute::<[i16; 8], int16x8_t>([0xce0, NEG10 as i16, 0, 0, 0, 0, 0, 0])
},
};
let mut c = ptr::addr_of!(CONSTS);
// Compiler barrier, or clang doesn't load from memory and generates 15
// more instructions.
let c = unsafe {
asm!("/*{0}*/", inout(reg) c);
&*c
};
let mut hundred_million = c.hundred_million;
// Compiler barrier, or clang narrows the load to 32-bit and unpairs it.
unsafe {
asm!("/*{0}*/", inout(reg) hundred_million);
}
// Equivalent to abbccddee = value / 100000000, ffgghhii = value % 100000000.
let abbccddee = (umul128(value, c.mul_const) >> 90) as u64;
let ffgghhii = value - abbccddee * hundred_million;
// We could probably make this bit faster, but we're preferring to
// reuse the constants for now.
let a = (umul128(abbccddee, c.mul_const) >> 90) as u64;
let bbccddee = abbccddee - a * hundred_million;
buffer = unsafe { write_if(buffer, a as u32, extra_digit) };
unsafe {
let ffgghhii_bbccddee_64: uint64x1_t =
mem::transmute::<u64, uint64x1_t>((ffgghhii << 32) | bbccddee);
let bbccddee_ffgghhii: int32x2_t = vreinterpret_s32_u64(ffgghhii_bbccddee_64);
let bbcc_ffgg: int32x2_t = vreinterpret_s32_u32(vshr_n_u32(
vreinterpret_u32_s32(vqdmulh_n_s32(
bbccddee_ffgghhii,
mem::transmute::<int32x4_t, [i32; 4]>(c.multipliers32)[0],
)),
9,
));
let ddee_bbcc_hhii_ffgg_32: int32x2_t = vmla_n_s32(
bbccddee_ffgghhii,
bbcc_ffgg,
mem::transmute::<int32x4_t, [i32; 4]>(c.multipliers32)[1],
);
let mut ddee_bbcc_hhii_ffgg: int32x4_t =
vreinterpretq_s32_u32(vshll_n_u16(vreinterpret_u16_s32(ddee_bbcc_hhii_ffgg_32), 0));
// Compiler barrier, or clang breaks the subsequent MLA into UADDW +
// MUL.
asm!("/*{:v}*/", inout(vreg) ddee_bbcc_hhii_ffgg);
let dd_bb_hh_ff: int32x4_t = vqdmulhq_n_s32(
ddee_bbcc_hhii_ffgg,
mem::transmute::<int32x4_t, [i32; 4]>(c.multipliers32)[2],
);
let ee_dd_cc_bb_ii_hh_gg_ff: int16x8_t = vreinterpretq_s16_s32(vmlaq_n_s32(
ddee_bbcc_hhii_ffgg,
dd_bb_hh_ff,
mem::transmute::<int32x4_t, [i32; 4]>(c.multipliers32)[3],
));
let high_10s: int16x8_t = vqdmulhq_n_s16(
ee_dd_cc_bb_ii_hh_gg_ff,
mem::transmute::<int16x8_t, [i16; 8]>(c.multipliers16)[0],
);
let digits: uint8x16_t = vrev64q_u8(vreinterpretq_u8_s16(vmlaq_n_s16(
ee_dd_cc_bb_ii_hh_gg_ff,
high_10s,
mem::transmute::<int16x8_t, [i16; 8]>(c.multipliers16)[1],
)));
let str: uint16x8_t = vaddq_u16(
vreinterpretq_u16_u8(digits),
vreinterpretq_u16_s8(vdupq_n_s8(b'0' as i8)),
);
buffer.cast::<uint16x8_t>().write_unaligned(str);
let is_not_zero: uint16x8_t =
vreinterpretq_u16_u8(vcgtzq_s8(vreinterpretq_s8_u8(digits)));
let zeros: u64 = vget_lane_u64(vreinterpret_u64_u8(vshrn_n_u16(is_not_zero, 4)), 0);
buffer.add(16 - (zeros.leading_zeros() as usize >> 2))
}
}
#[cfg(all(target_arch = "x86_64", target_feature = "sse2", not(miri)))]
{
use crate::stdarch_x86::*;
let abbccddee = (value / 100_000_000) as u32;
let ffgghhii = (value % 100_000_000) as u32;
let a = abbccddee / 100_000_000;
let bbccddee = abbccddee % 100_000_000;
buffer = unsafe { write_if(buffer, a, extra_digit) };
#[repr(C, align(64))]
struct Consts {
div10k: u128,
neg10k: u128,
div100: u128,
div10: u128,
#[cfg(target_feature = "sse4.1")]
neg100: u128,
#[cfg(target_feature = "sse4.1")]
neg10: u128,
#[cfg(target_feature = "sse4.1")]
bswap: u128,
#[cfg(not(target_feature = "sse4.1"))]
hundred: u128,
#[cfg(not(target_feature = "sse4.1"))]
moddiv10: u128,
zeros: u128,
}
impl Consts {
const fn splat64(x: u64) -> u128 {
((x as u128) << 64) | x as u128
}
const fn splat32(x: u32) -> u128 {
Self::splat64(((x as u64) << 32) | x as u64)
}
const fn splat16(x: u16) -> u128 {
Self::splat32(((x as u32) << 16) | x as u32)
}
#[cfg(target_feature = "sse4.1")]
const fn pack8(a: u8, b: u8, c: u8, d: u8, e: u8, f: u8, g: u8, h: u8) -> u64 {
((h as u64) << 56)
| ((g as u64) << 48)
| ((f as u64) << 40)
| ((e as u64) << 32)
| ((d as u64) << 24)
| ((c as u64) << 16)
| ((b as u64) << 8)
| a as u64
}
}
static CONSTS: Consts = Consts {
div10k: Consts::splat64(DIV10K_SIG as u64),
neg10k: Consts::splat64(NEG10K as u64),
div100: Consts::splat32(DIV100_SIG),
div10: Consts::splat16(((1u32 << 16) / 10 + 1) as u16),
#[cfg(target_feature = "sse4.1")]
neg100: Consts::splat32(NEG100),
#[cfg(target_feature = "sse4.1")]
neg10: Consts::splat16((1 << 8) - 10),
#[cfg(target_feature = "sse4.1")]
bswap: Consts::pack8(15, 14, 13, 12, 11, 10, 9, 8) as u128
| (Consts::pack8(7, 6, 5, 4, 3, 2, 1, 0) as u128) << 64,
#[cfg(not(target_feature = "sse4.1"))]
hundred: Consts::splat32(100),
#[cfg(not(target_feature = "sse4.1"))]
moddiv10: Consts::splat16(10 * (1 << 8) - 1),
zeros: Consts::splat64(ZEROS),
};
let mut c = ptr::addr_of!(CONSTS);
// Load constants from memory.
unsafe {
asm!("/*{0}*/", inout(reg) c);
}
let div10k = unsafe { _mm_load_si128(ptr::addr_of!((*c).div10k).cast::<__m128i>()) };
let neg10k = unsafe { _mm_load_si128(ptr::addr_of!((*c).neg10k).cast::<__m128i>()) };
let div100 = unsafe { _mm_load_si128(ptr::addr_of!((*c).div100).cast::<__m128i>()) };
let div10 = unsafe { _mm_load_si128(ptr::addr_of!((*c).div10).cast::<__m128i>()) };
#[cfg(target_feature = "sse4.1")]
let neg100 = unsafe { _mm_load_si128(ptr::addr_of!((*c).neg100).cast::<__m128i>()) };
#[cfg(target_feature = "sse4.1")]
let neg10 = unsafe { _mm_load_si128(ptr::addr_of!((*c).neg10).cast::<__m128i>()) };
#[cfg(target_feature = "sse4.1")]
let bswap = unsafe { _mm_load_si128(ptr::addr_of!((*c).bswap).cast::<__m128i>()) };
#[cfg(not(target_feature = "sse4.1"))]
let hundred = unsafe { _mm_load_si128(ptr::addr_of!((*c).hundred).cast::<__m128i>()) };
#[cfg(not(target_feature = "sse4.1"))]
let moddiv10 = unsafe { _mm_load_si128(ptr::addr_of!((*c).moddiv10).cast::<__m128i>()) };
let zeros = unsafe { _mm_load_si128(ptr::addr_of!((*c).zeros).cast::<__m128i>()) };
// The BCD sequences are based on ones provided by Xiang JunBo.
unsafe {
let x: __m128i = _mm_set_epi64x(i64::from(bbccddee), i64::from(ffgghhii));
let y: __m128i = _mm_add_epi64(
x,
_mm_mul_epu32(neg10k, _mm_srli_epi64(_mm_mul_epu32(x, div10k), DIV10K_EXP)),
);
#[cfg(target_feature = "sse4.1")]
let bcd: __m128i = {
// _mm_mullo_epi32 is SSE 4.1
let z: __m128i = _mm_add_epi64(
y,
_mm_mullo_epi32(neg100, _mm_srli_epi32(_mm_mulhi_epu16(y, div100), 3)),
);
let big_endian_bcd: __m128i =
_mm_add_epi64(z, _mm_mullo_epi16(neg10, _mm_mulhi_epu16(z, div10)));
// SSSE3
_mm_shuffle_epi8(big_endian_bcd, bswap)
};
#[cfg(not(target_feature = "sse4.1"))]
let bcd: __m128i = {
let y_div_100: __m128i = _mm_srli_epi16(_mm_mulhi_epu16(y, div100), 3);
let y_mod_100: __m128i = _mm_sub_epi16(y, _mm_mullo_epi16(y_div_100, hundred));
let z: __m128i = _mm_or_si128(_mm_slli_epi32(y_mod_100, 16), y_div_100);
let bcd_shuffled: __m128i = _mm_sub_epi16(
_mm_slli_epi16(z, 8),
_mm_mullo_epi16(moddiv10, _mm_mulhi_epu16(z, div10)),
);
_mm_shuffle_epi32(bcd_shuffled, _MM_SHUFFLE(0, 1, 2, 3))
};
let digits = _mm_or_si128(bcd, zeros);
// Count leading zeros.
let mask128: __m128i = _mm_cmpgt_epi8(bcd, _mm_setzero_si128());
let mask = _mm_movemask_epi8(mask128) as u32;
let len = 32 - mask.leading_zeros() as usize;
_mm_storeu_si128(buffer.cast::<__m128i>(), digits);
buffer.add(len)
}
}
}
struct ToDecimalResult {
sig: i64,
exp: i32,
}
#[cfg_attr(feature = "no-panic", no_panic)]
#[inline]
fn to_decimal_schubfach<UInt>(bin_sig: UInt, bin_exp: i64, regular: bool) -> ToDecimalResult
where
UInt: traits::UInt,
{
let num_bits = mem::size_of::<UInt>() as i32 * 8;
let dec_exp = compute_dec_exp(bin_exp as i32, regular);
let exp_shift = unsafe { compute_exp_shift::<UInt, false>(bin_exp as i32, dec_exp) };
let mut pow10 = unsafe { POW10_SIGNIFICANDS.get_unchecked(-dec_exp) };
// Fallback to Schubfach to guarantee correctness in boundary cases. This
// requires switching to strict overestimates of powers of 10.
if num_bits == 64 {
pow10.lo += 1;
} else {
pow10.hi += 1;
}
// Shift the significand so that boundaries are integer.
const BOUND_SHIFT: u32 = 2;
let bin_sig_shifted = bin_sig << BOUND_SHIFT;
// Compute the estimates of lower and upper bounds of the rounding interval
// by multiplying them by the power of 10 and applying modified rounding.
let lsb = bin_sig & UInt::from(1);
let lower = (bin_sig_shifted - (UInt::from(regular) + UInt::from(1))) << exp_shift;
let lower = umulhi_inexact_to_odd(pow10.hi, pow10.lo, lower) + lsb;
let upper = (bin_sig_shifted + UInt::from(2)) << exp_shift;
let upper = umulhi_inexact_to_odd(pow10.hi, pow10.lo, upper) - lsb;
// The idea of using a single shorter candidate is by Cassio Neri.
// It is less or equal to the upper bound by construction.
let shorter = (upper >> BOUND_SHIFT) / UInt::from(10) * UInt::from(10);
if (shorter << BOUND_SHIFT) >= lower {
return ToDecimalResult {
sig: shorter.into() as i64,
exp: dec_exp,
};
}
let scaled_sig = umulhi_inexact_to_odd(pow10.hi, pow10.lo, bin_sig_shifted << exp_shift);
let longer_below = scaled_sig >> BOUND_SHIFT;
let longer_above = longer_below + UInt::from(1);
// Pick the closest of longer_below and longer_above and check if it's in
// the rounding interval.
let cmp = scaled_sig
.wrapping_sub((longer_below + longer_above) << 1)
.to_signed();
let below_closer = cmp < UInt::from(0).to_signed()
|| (cmp == UInt::from(0).to_signed() && (longer_below & UInt::from(1)) == UInt::from(0));
let below_in = (longer_below << BOUND_SHIFT) >= lower;
let dec_sig = if below_closer & below_in {
longer_below
} else {
longer_above
};
ToDecimalResult {
sig: dec_sig.into() as i64,
exp: dec_exp,
}
}
// Here be 🐉s.
// Converts a binary FP number bin_sig * 2**bin_exp to the shortest decimal
// representation, where bin_exp = raw_exp - exp_offset.
#[cfg_attr(feature = "no-panic", no_panic)]
#[inline]
fn to_decimal_fast<Float, UInt>(bin_sig: UInt, raw_exp: i64, regular: bool) -> ToDecimalResult
where
Float: FloatTraits,
UInt: traits::UInt,
{
let bin_exp = raw_exp - i64::from(Float::EXP_OFFSET);
let num_bits = mem::size_of::<UInt>() as i32 * 8;
// An optimization from yy by Yaoyuan Guo:
while regular {
let dec_exp = if USE_UMUL128_HI64 {
umul128_hi64(bin_exp as u64, 0x4d10500000000000) as i32
} else {
compute_dec_exp(bin_exp as i32, true)
};
let exp_shift = unsafe { compute_exp_shift::<UInt, true>(bin_exp as i32, dec_exp) };
let pow10 = unsafe { POW10_SIGNIFICANDS.get_unchecked(-dec_exp) };
let integral; // integral part of bin_sig * pow10
let fractional; // fractional part of bin_sig * pow10
if num_bits == 64 {
let p = umul192_hi128(pow10.hi, pow10.lo, (bin_sig << exp_shift).into());
integral = UInt::truncate(p.hi);
fractional = p.lo;
} else {
let p = umul128(pow10.hi, (bin_sig << exp_shift).into());
integral = UInt::truncate((p >> 64) as u64);
fractional = p as u64;
}
const HALF_ULP: u64 = 1 << 63;
// Exact half-ulp tie when rounding to nearest integer.
let cmp = fractional.wrapping_sub(HALF_ULP) as i64;
if cmp == 0 {
break;
}
// An optimization of integral % 10 by Dougall Johnson. Relies on range
// calculation: (max_bin_sig << max_exp_shift) * max_u128.
// (1 << 63) / 5 == (1 << 64) / 10 without an intermediate int128.
const DIV10_SIG64: u64 = (1 << 63) / 5 + 1;
let div10 = umul128_hi64(integral.into(), DIV10_SIG64);
#[allow(unused_mut)]
let mut digit = integral.into() - div10 * 10;
// or it narrows to 32-bit and doesn't use madd/msub
#[cfg(all(any(target_arch = "aarch64", target_arch = "x86_64"), not(miri)))]
unsafe {
asm!("/*{0}*/", inout(reg) digit);
}
// Switch to a fixed-point representation with the least significant
// integral digit in the upper bits and fractional digits in the lower
// bits.
let num_integral_bits = if num_bits == 64 { 4 } else { 32 };
let num_fractional_bits = 64 - num_integral_bits;
let ten = 10u64 << num_fractional_bits;
// Fixed-point remainder of the scaled significand modulo 10.
let scaled_sig_mod10 = (digit << num_fractional_bits) | (fractional >> num_integral_bits);
// scaled_half_ulp = 0.5 * pow10 in the fixed-point format.
// dec_exp is chosen so that 10**dec_exp <= 2**bin_exp < 10**(dec_exp + 1).
// Since 1ulp == 2**bin_exp it will be in the range [1, 10) after scaling
// by 10**dec_exp. Add 1 to combine the shift with division by two.
let scaled_half_ulp = pow10.hi >> (num_integral_bits - exp_shift + 1);
let upper = scaled_sig_mod10 + scaled_half_ulp;
// value = 5.0507837461e-27
// next = 5.0507837461000010e-27
//
// c = integral.fractional' = 50507837461000003.153987... (value)
// 50507837461000010.328635... (next)
// scaled_half_ulp = 3.587324...
//
// fractional' = fractional / 2**64, fractional = 2840565642863009226
//
// 50507837461000000 c upper 50507837461000010
// s l| L | S
// ───┬────┬────┼────┬────┬────┼*-──┼────┬────┬───*┬────┬────┬────┼-*--┬───
// 8 9 0 1 2 3 4 5 6 7 8 9 0 | 1
// └─────────────────┼─────────────────┘ next
// 1ulp
//
// s - shorter underestimate, S - shorter overestimate
// l - longer underestimate, L - longer overestimate
// Check for boundary case when rounding down to nearest 10 and
// near-boundary case when rounding up to nearest 10.
// Case where upper == ten is insufficient: 1.342178e+08f.
if ten.wrapping_sub(upper) <= 1 // upper == ten || upper == ten - 1
|| scaled_sig_mod10 == scaled_half_ulp
{
break;
}
let shorter = (integral.into() - digit) as i64;
let longer = (integral.into() + u64::from(cmp >= 0)) as i64;
let dec_sig = select_if_less(scaled_sig_mod10, scaled_half_ulp, shorter, longer);
return ToDecimalResult {
sig: select_if_less(ten, upper, shorter + 10, dec_sig),
exp: dec_exp,
};
}
to_decimal_schubfach(bin_sig, bin_exp, regular)
}
/// Writes the shortest correctly rounded decimal representation of `value` to
/// `buffer`. `buffer` should point to a buffer of size `buffer_size` or larger.
#[cfg_attr(feature = "no-panic", no_panic)]
unsafe fn write<Float>(value: Float, mut buffer: *mut u8) -> *mut u8
where
Float: FloatTraits,
{
let bits = value.to_bits();
// It is beneficial to extract exponent and significand early.
let bin_exp = Float::get_exp(bits); // binary exponent
let bin_sig = Float::get_sig(bits); // binary significand
unsafe {
*buffer = b'-';
}
buffer = unsafe { buffer.add(usize::from(Float::is_negative(bits))) };
let mut dec;
let threshold = if Float::NUM_BITS == 64 {
10_000_000_000_000_000
} else {
100_000_000
};
if bin_exp == 0 {
if bin_sig == Float::SigType::from(0) {
return unsafe {
*buffer = b'0';
*buffer.add(1) = b'.';
*buffer.add(2) = b'0';
buffer.add(3)
};
}
dec = to_decimal_schubfach(bin_sig, i64::from(1 - Float::EXP_OFFSET), true);
while dec.sig < threshold {
dec.sig *= 10;
dec.exp -= 1;
}
} else {
dec = to_decimal_fast::<Float, Float::SigType>(
bin_sig | Float::IMPLICIT_BIT,
bin_exp,
bin_sig != Float::SigType::from(0),
);
}
let mut dec_exp = dec.exp;
let extra_digit = dec.sig >= threshold;
dec_exp += Float::MAX_DIGITS10 as i32 - 2 + i32::from(extra_digit);
if Float::NUM_BITS == 32 && dec.sig < 10_000_000 {
dec.sig *= 10;
dec_exp -= 1;
}
// Write significand.
let end = unsafe { write_significand::<Float>(buffer.add(1), dec.sig as u64, extra_digit) };
let length = unsafe { end.offset_from(buffer.add(1)) } as usize;
if Float::NUM_BITS == 32 && (-6..=12).contains(&dec_exp)
|| Float::NUM_BITS == 64 && (-5..=15).contains(&dec_exp)
{
if length as i32 - 1 <= dec_exp {
// 1234e7 -> 12340000000.0
return unsafe {
ptr::copy(buffer.add(1), buffer, length);
ptr::write_bytes(buffer.add(length), b'0', dec_exp as usize + 3 - length);
*buffer.add(dec_exp as usize + 1) = b'.';
buffer.add(dec_exp as usize + 3)
};
} else if 0 <= dec_exp {
// 1234e-2 -> 12.34
return unsafe {
ptr::copy(buffer.add(1), buffer, dec_exp as usize + 1);
*buffer.add(dec_exp as usize + 1) = b'.';
buffer.add(length + 1)
};
} else {
// 1234e-6 -> 0.001234
return unsafe {
ptr::copy(buffer.add(1), buffer.add((1 - dec_exp) as usize), length);
ptr::write_bytes(buffer, b'0', (1 - dec_exp) as usize);
*buffer.add(1) = b'.';
buffer.add((1 - dec_exp) as usize + length)
};
}
}
unsafe {
// 1234e30 -> 1.234e33
*buffer = *buffer.add(1);
*buffer.add(1) = b'.';
}
buffer = unsafe { buffer.add(length + usize::from(length > 1)) };
// Write exponent.
let sign_ptr = buffer;
let e_sign = if dec_exp >= 0 {
(u16::from(b'+') << 8) | u16::from(b'e')
} else {
(u16::from(b'-') << 8) | u16::from(b'e')
};
buffer = unsafe { buffer.add(1) };
dec_exp = if dec_exp >= 0 { dec_exp } else { -dec_exp };
buffer = unsafe { buffer.add(usize::from(dec_exp >= 10)) };
if Float::MIN_10_EXP > -100 && Float::MAX_10_EXP < 100 {
unsafe {
buffer
.cast::<u16>()
.write_unaligned(*digits2(dec_exp as usize));
sign_ptr.cast::<u16>().write_unaligned(e_sign.to_le());
return buffer.add(2);
}
}
// digit = dec_exp / 100
let digit = if USE_UMUL128_HI64 {
umul128_hi64(dec_exp as u64, 0x290000000000000) as u32
} else {
(dec_exp as u32 * DIV100_SIG) >> DIV100_EXP
};
unsafe {
*buffer = b'0' + digit as u8;
}
buffer = unsafe { buffer.add(usize::from(dec_exp >= 100)) };
unsafe {
buffer
.cast::<u16>()
.write_unaligned(*digits2((dec_exp as u32 - digit * 100) as usize));
sign_ptr.cast::<u16>().write_unaligned(e_sign.to_le());
buffer.add(2)
}
}
/// Safe API for formatting floating point numbers to text.
///
/// ## Example
///
/// ```
/// let mut buffer = zmij::Buffer::new();
/// let printed = buffer.format_finite(1.234);
/// assert_eq!(printed, "1.234");
/// ```
pub struct Buffer {
bytes: [MaybeUninit<u8>; BUFFER_SIZE],
}
impl Buffer {
/// This is a cheap operation; you don't need to worry about reusing buffers
/// for efficiency.
#[inline]
#[cfg_attr(feature = "no-panic", no_panic)]
pub fn new() -> Self {
let bytes = [MaybeUninit::<u8>::uninit(); BUFFER_SIZE];
Buffer { bytes }
}
/// Print a floating point number into this buffer and return a reference to
/// its string representation within the buffer.
///
/// # Special cases
///
/// This function formats NaN as the string "NaN", positive infinity as
/// "inf", and negative infinity as "-inf" to match std::fmt.
///
/// If your input is known to be finite, you may get better performance by
/// calling the `format_finite` method instead of `format` to avoid the
/// checks for special cases.
#[cfg_attr(feature = "no-panic", no_panic)]
pub fn format<F: Float>(&mut self, f: F) -> &str {
if f.is_nonfinite() {
f.format_nonfinite()
} else {
self.format_finite(f)
}
}
/// Print a floating point number into this buffer and return a reference to
/// its string representation within the buffer.
///
/// # Special cases
///
/// This function **does not** check for NaN or infinity. If the input
/// number is not a finite float, the printed representation will be some
/// correctly formatted but unspecified numerical value.
///
/// Please check [`is_finite`] yourself before calling this function, or
/// check [`is_nan`] and [`is_infinite`] and handle those cases yourself.
///
/// [`is_finite`]: f64::is_finite
/// [`is_nan`]: f64::is_nan
/// [`is_infinite`]: f64::is_infinite
#[cfg_attr(feature = "no-panic", no_panic)]
pub fn format_finite<F: Float>(&mut self, f: F) -> &str {
unsafe {
let end = f.write_to_zmij_buffer(self.bytes.as_mut_ptr().cast::<u8>());
let len = end.offset_from(self.bytes.as_ptr().cast::<u8>()) as usize;
let slice = slice::from_raw_parts(self.bytes.as_ptr().cast::<u8>(), len);
str::from_utf8_unchecked(slice)
}
}
}
/// A floating point number, f32 or f64, that can be written into a
/// [`zmij::Buffer`][Buffer].
///
/// This trait is sealed and cannot be implemented for types outside of the
/// `zmij` crate.
#[allow(unknown_lints)] // rustc older than 1.74
#[allow(private_bounds)]
pub trait Float: private::Sealed {}
impl Float for f32 {}
impl Float for f64 {}
mod private {
pub trait Sealed: crate::traits::Float {
fn is_nonfinite(self) -> bool;
fn format_nonfinite(self) -> &'static str;
unsafe fn write_to_zmij_buffer(self, buffer: *mut u8) -> *mut u8;
}
impl Sealed for f32 {
#[inline]
fn is_nonfinite(self) -> bool {
const EXP_MASK: u32 = 0x7f800000;
let bits = self.to_bits();
bits & EXP_MASK == EXP_MASK
}
#[cold]
#[cfg_attr(feature = "no-panic", inline)]
fn format_nonfinite(self) -> &'static str {
const MANTISSA_MASK: u32 = 0x007fffff;
const SIGN_MASK: u32 = 0x80000000;
let bits = self.to_bits();
if bits & MANTISSA_MASK != 0 {
crate::NAN
} else if bits & SIGN_MASK != 0 {
crate::NEG_INFINITY
} else {
crate::INFINITY
}
}
#[cfg_attr(feature = "no-panic", inline)]
unsafe fn write_to_zmij_buffer(self, buffer: *mut u8) -> *mut u8 {
unsafe { crate::write(self, buffer) }
}
}
impl Sealed for f64 {
#[inline]
fn is_nonfinite(self) -> bool {
const EXP_MASK: u64 = 0x7ff0000000000000;
let bits = self.to_bits();
bits & EXP_MASK == EXP_MASK
}
#[cold]
#[cfg_attr(feature = "no-panic", inline)]
fn format_nonfinite(self) -> &'static str {
const MANTISSA_MASK: u64 = 0x000fffffffffffff;
const SIGN_MASK: u64 = 0x8000000000000000;
let bits = self.to_bits();
if bits & MANTISSA_MASK != 0 {
crate::NAN
} else if bits & SIGN_MASK != 0 {
crate::NEG_INFINITY
} else {
crate::INFINITY
}
}
#[cfg_attr(feature = "no-panic", inline)]
unsafe fn write_to_zmij_buffer(self, buffer: *mut u8) -> *mut u8 {
unsafe { crate::write(self, buffer) }
}
}
}
impl Default for Buffer {
#[inline]
#[cfg_attr(feature = "no-panic", no_panic)]
fn default() -> Self {
Buffer::new()
}
}